(bayesian_workflow)=
The Bayesian Workflow: COVID-19 Outbreak Modeling
:::{post} Jun 16, 2025 :tags: workflow :category: intermediate, how-to :author: Thomas Wiecki, Chris Fonnesbeck :::
Bayesian modeling is a robust approach for drawing conclusions from data. Successful modeling involves an interplay among statistical models, subject matter knowledge, and computational techniques. In building Bayesian models, it is easy to get carried away with complex models from the outset, often leading to an unsatisfactory final result (or a dead end). To avoid common model development pitfalls, a structured approach is helpful. The Bayesian workflow (Gelman et al.) is a systematic approach to building, validating, and refining probabilistic models, ensuring that the models are robust, interpretable, and useful for decision-making. The workflow's iterative nature ensures that modeling assumptions are tested and refined as the model grows, leading to more reliable results.
This workflow is particularly powerful in high-level probabilistic programming environments like PyMC, where the ability to rapidly prototype and iterate on complex statistical models enables practitioners to focus on the modeling process rather than the underlying computational details. The workflow invlolves moving from simple models--via prior checks, fitting, diagnostics, and refinement--through to a final product that satisfies the analytic goals, making sure that computational and conceptual issues are identified and addressed systematically as they are encountered.
Below we demonstrate the Bayesian workflow using COVID-19 case data, showing how to progress from very basic, unrealistic models to more sophisticated formulations, highlighting the critical role of model checking and validation at each step. Here we are not looking to develop a state-of-the-art epidemiological model, but rather to demonstrate how to iterate from a simple model to a more complex one.
Bayesian methods offer several fundamental strengths that make it particularly valuable for building robust statistical models. Its great flexibility allows practitioners to build remarkably complex models from simple building blocks. The framework provides a principled way of dealing with uncertainty, capturing not just the most likely outcome but the complete distribution of all possible outcomes. Critically, Bayesian methods allow expert information to guide model development through the use of informative priors, incorporating domain knowledge directly into the analysis.
In this section you'll learn:
- How to go from data to a model idea
- How to find priors for your model
- How to evaluate a model
- How to iteratively improve a model
- How to forecast into the future
- How powerful generative modeling can be
The Bayesian Workflow: An Overview
Before diving into our COVID-19 modeling example, let's understand the key stages of the Bayesian workflow as outlined by Gelman et al. (2020). This workflow is not a linear process but rather an iterative cycle where we continuously refine our understanding.
:::{admonition} The Bayesian Workflow Stages :class: tip
- Conceptual model building: Translate domain knowledge into statistical assumptions
- Prior predictive simulation: Check if priors generate reasonable data
- Computational implementation: Code the model and ensure it runs
- Fitting and diagnostics: Estimate parameters and check convergence
- Model evaluation: Assess model fit using posterior predictive checks
- Model comparison: Compare alternative models systematically
- Model expansion or simplification: Iterate based on findings
- Decision analysis: Use the model for predictions or decisions :::
Throughout this tutorial, we'll explicitly mark which stage of the workflow we're in, helping you understand not just what we're doing, but why we're doing it.
Load and Explore Data
:::{admonition} Workflow Stage: Conceptual Model Building :class: note
We begin by understanding our data and its context. This exploratory phase informs our initial modeling decisions. :::
First we'll load data on COVID-19 cases from the World Health Organization (WHO). In order simplify the analysis we will restrict the dataset to the time after 100 cases were confirmed (as reporting is often very noisy prior to that). It also allows us to align countries with each other for easier comparison.
Bayesian Workflow
Next, we will start developing a model of the spread. These models will start out simple (and poor) but we will iteratively improve them. A good workflow to adopt when developing your own models is:
- Plot the data - Understand patterns and features
- Build model - Start simple, add complexity gradually
- Run prior predictive check - Ensure priors generate sensible data
- Fit model - Estimate parameters from data
- Assess convergence - Verify computational reliability
- Check model fit - Compare predictions to observations
- Improve model - Address identified deficiencies
1. Plot the data
We will look at German COVID-19 cases. At first, we will only look at the first 30 days after Germany crossed 100 cases, later we will look at the full data.
Look at the above plot and think about what type of model you would build to capture this pattern. What mathematical function might describe this growth?
Step 2: Build Models - Starting with a Baseline
:::{admonition} Workflow Stage: Model Building :class: note
Before jumping to complex models, we establish a baseline. This helps us understand how much we gain from added complexity. :::
A Baseline Model
A critical but often overlooked step is establishing a baseline model. This gives us a reference point to judge whether our more complex models are actually capturing meaningful patterns.
The trajectory of cumulative cases kind of looks exponential. This matches with knowledge from epidemiology whereas early in an epidemic it grows exponentially.
:::{admonition} Model Critique :class: tip
Before fitting, consider: What assumptions does this model make? Are there any issues you can identify just from the model specification? Is there anything you would have done differently? :::
Step 3: Run Prior Predictive Check
:::{admonition} Workflow Stage: Prior Predictive Simulation :class: note
Before fitting, we check if our priors generate reasonable data. This is a crucial but often skipped step! :::
Without even fitting the model to our data, we generate new potential data from our priors. Usually we have less intuition about the parameter space, where we define our priors, and more intuition about what data we might expect to see. A prior predictive check thus allows us to make sure the model can generate the types of data we expect to see.
The process works as follows:
- Pick a point from the prior $\theta_i$
- Generate data set $x_i \sim f(\theta_i)$ where $f$ is our likelihood function (e.g. normal)
- Rinse and repeat $n$ times
:::{admonition} What's Wrong With This Model? :class: warning
Our prior predictive check reveals several problems:
- Negative cases: Impossible in reality
- Starting near zero: We conditioned on 100+ cases
- Normal likelihood: Allows negative values and symmetric errors
This demonstrates the value of prior predictive checking! :::
Let's improve our model. The presence of negative cases is due to us using a Normal likelihood. Instead, let's use a NegativeBinomial, which is similar to Poisson which is commonly used for count-data but has an extra dispersion parameter that allows more flexiblity in modeling the variance of the data.
We will also change the prior of the intercept to be centered at 100 and tighten the prior of the slope.
The negative binomial distribution uses an overdispersion parameter, which we will describe using a gamma distribution. A companion package called preliz, a library for prior distribution elicitation, has a nice utility called maxent that will help us parameterize this prior, as the gamma distribution is not as intuitive to work with as the normal distribution.
:::{admonition} Progress! :class: success
Much better! No negative cases, and the scale looks more reasonable. But we can still incorporate more domain knowledge. :::
Model 3: Incorporating Domain Constraints
We know that:
- The intercept cannot be below 100 (by construction of our data)
- The growth rate must be positive
Let's encode this knowledge: we use the PyMC HalfNormal distribution for the intercept prior; we can apply the same for the slope which we know is not going to be negative.
Note that even though the intercept parameter can not be below 100 now, we still see data generated at below hundred. Why?
Step 4: Fit Model
:::{admonition} Workflow Stage: Model Fitting :class: note
Now we fit our model using MCMC. This is where the "Inference Button™" (pm.sample) comes in!
:::
Step 5: Assess Convergence
:::{admonition} Workflow Stage: Computational Diagnostics :class: note
Before trusting our results, we must verify that the sampler has converged properly. :::
:::{admonition} Convergence Checklist :class: success
✓ R-hat values: All close to 1.0 (< 1.01)
✓ Effective sample size: Reasonable for all parameters
✓ Trace plots: Show good mixing with no trends
✓ Energy plot: Marginal and energy distributions overlap well
Our model has converged successfully! :::
Model comparison
Let's quickly compare the two models we were able to sample from.
Model comparison requires the log-likelihoods of the respective models. For efficiency, these are not computed automatically, so we need to manually calculate them.
Now we can use the ArviZ compare function:
It seems like bounding the priors did not result in better fit. This is not unexpected because our change in prior was very small. We will still continue with model_exp3 because we have prior information that these parameters are bounded in this way.
Sensitivity Analysis
:::{admonition} Workflow Stage: Model Criticism :class: note
A crucial but often neglected step is understanding how sensitive our conclusions are to modeling choices. :::
Let's examine how our results change with different prior choices:
:::{admonition} Sensitivity Analysis Results :class: note
The posterior is relatively robust to prior choice when we have sufficient data. However, with limited data (early in the outbreak), prior choice matters more. This highlights the importance of:
- Using domain knowledge to set reasonable priors
- Checking sensitivity when data is limited
- Being transparent about prior choices :::
Step 6: Check Model Fit
:::{admonition} Workflow Stage: Model Evaluation :class: note
Posterior predictive checking is crucial for understanding how well our model captures the data-generating process. :::
Similar to the prior predictive, we can also generate new data by repeatedly taking samples from the posterior and generating data using these parameters. This process is called posterior predictive checking and is a crucial step in Bayesian model validation.
Posterior predictive checking works by:
- Taking parameter samples from the posterior distribution (which we already have from MCMC sampling)
- For each set of parameter values, generating new synthetic datasets using the same likelihood function as our model
- Comparing these synthetic datasets to our observed data
This allows us to assess whether our model can reproduce key features of the observed data. If the posterior predictive samples look very different from our actual data, it suggests our model may be missing important aspects of the data-generating process. Conversely, if the posterior predictive samples encompass our observed data well, it provides evidence that our model is capturing the essential patterns in the data.
OK, that does not look terrible; the data essentially behaves like a random draw from the model.
As an additional check, we can also inspect the model residuals.
:::{admonition} Residual Analysis :class: warning
Notice the systematic pattern in residuals - there is a bias that tends to increase over time. This suggests our exponential model may be too rigid for longer time periods. :::
Prediction and forecasting
:::{admonition} Workflow Stage: Decision Analysis :class: note
Models are often built for prediction. Let's see how our model performs on out-of-sample data. :::
We are often interested in predicting or forecasting. In PyMC, you can do so easily using pm.Data nodes, which provide a powerful mechanism for out-of-sample prediction and forecasting.
Wrapping your input data in pm.Data allows you to define data containers within a PyMC model that can be dynamically updated after model fitting. This is particularly useful for prediction scenarios where you want to:
- Train on observed data: Fit your model using the available training data
- Switch to prediction inputs: Replace the training data with new input values (e.g., future time points)
- Generate predictions: Use posterior predictive sampling to generate forecasts based on the fitted model
Let's demonstrate this approach by modifying our exponential growth model to use pm.Data nodes.
As we held data back before, we can now see how the predictions of the model
:::{admonition} Forecast Performance :class: warning
The exponential model severely overestimates future cases. This is a common issue with exponential growth models - they don't account for the natural limits on disease spread. :::
Step 7: Improve Model - Logistic Growth
:::{admonition} Workflow Stage: Model Expansion :class: note
Based on our findings, we need a model that can capture slowing growth. The logistic model is a natural choice. :::
The logistic model incorporates a "carrying capacity" - a maximum number of cases that limits growth:
where $K$ is the carrying capacity, $r$ is the growth rate, and $A$ determines the curve's midpoint.
Logistic model
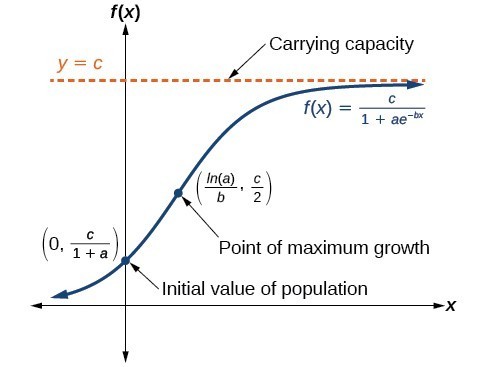
:::{admonition} Improved Fit! :class: success
The logistic model captures the slowing growth much better than the exponential model. The carrying capacity parameter allows the model to naturally plateau. :::
What is the difference between the residuals from before?
Model comparison
In order to compare our models we first need to refit with the longer data we now have. Fortunately we can easily swap out the data because these are pm.Data now.
As you can see, the logistic model provides a much better fit to the data.
Model Validation: Testing on Another Country
:::{admonition} Workflow Stage: Model Criticism :class: note
A key test of our model is whether it generalizes to other contexts. Let's try the US data. :::
The US data looks quite different - there appear to be multiple waves. Let's see how our logistic model handles this:
:::{admonition} Model Limitations Revealed :class: warning
The simple logistic model fails to capture the multiple waves in US data. This reveals important limitations:
- Single logistic curves assume one continuous outbreak
- Real epidemics have multiple waves due to policy changes, new variants, etc.
- Different countries have different dynamics
This motivates additional model improvement! :::
Exercises for Further Exploration
-
Time-Varying Parameters: Extend the logistic model to allow the growth rate to change over time (hint: use changepoint models)
-
External Covariates: Add policy intervention dates as covariates to model their effect on transmission
-
Model Averaging: Instead of selecting one model, try Bayesian model averaging
-
Predictive Validation: Hold out the last 30 days of data and evaluate forecast accuracy
-
Prior Elicitation: Interview a domain expert and encode their knowledge as priors
References
Gelman, A., Vehtari, A., Simpson, D., Margossian, C. C., Carpenter, B., Yao, Y., ... & Modrák, M. (2020). Bayesian workflow. arXiv preprint arXiv:2011.01808.
Authors
- Originally authored by Thomas Wiecki in 2020
- Adapted and expanded by Chris Fonnesbeck in June 2025
Watermark
:::{include} ../page_footer.md :::